
I’ve become a huge fan of Qwen lately. Alibaba’s team has been releasing open-source models at a pace that feels deliberate — not experimental side projects, but serious systems that go head-to-head with proprietary stacks from OpenAI, Anthropic, and Gemini. Their recent release, Qwen3-TTS, immediately caught my attention. As an engineer, I care less about hype and more about architecture, latency, and whether I can actually run the thing without melting my GPU. So on a quiet Sunday evening — throttling the fans of my black beast like it was preparing for takeoff — I downloaded Qwen3-TTS-12Hz-1.7B-Base, wired up an inference pipeline, and started experimenting. Naturally, this included the highly scientific benchmark of making a fictional Mr. Donald Trump congratulating over telephone. 😆
Technically, Qwen3-TTS is not a legacy pipeline stitched from acoustic models and a separate vocoder. It follows an end-to-end generative architecture that treats speech as token prediction, much like an LLM treats text. At its core is a transformer trained to generate discrete audio tokens produced by a dedicated tokenizer: Qwen3-TTS-Tokenizer-12Hz. This tokenizer compresses waveform audio into semantic-acoustic tokens at a 12 Hz rate, dramatically shortening sequence length while preserving perceptual quality. That compression ratio is not just elegant — it’s the reason the model can stream speech in real time instead of making you wait awkwardly while your GPU negotiates with physics.
This architecture effectively collapses the traditional TTS stack. Instead of text → phonemes → spectrogram → vocoder, Qwen3-TTS directly generates audio tokens from text and conditioning signals in a unified loop. Fewer stages mean fewer cascading errors and tighter alignment between linguistic structure and prosody. The model learns rhythm, emphasis, and expression jointly with language. More importantly for real applications, the system is built for incremental streaming. Tokens are emitted continuously and decoded on the fly, so audio playback can begin almost immediately. In practice, this feels less like rendering audio and more like listening to a live speaker who just happens to live inside your GPU.
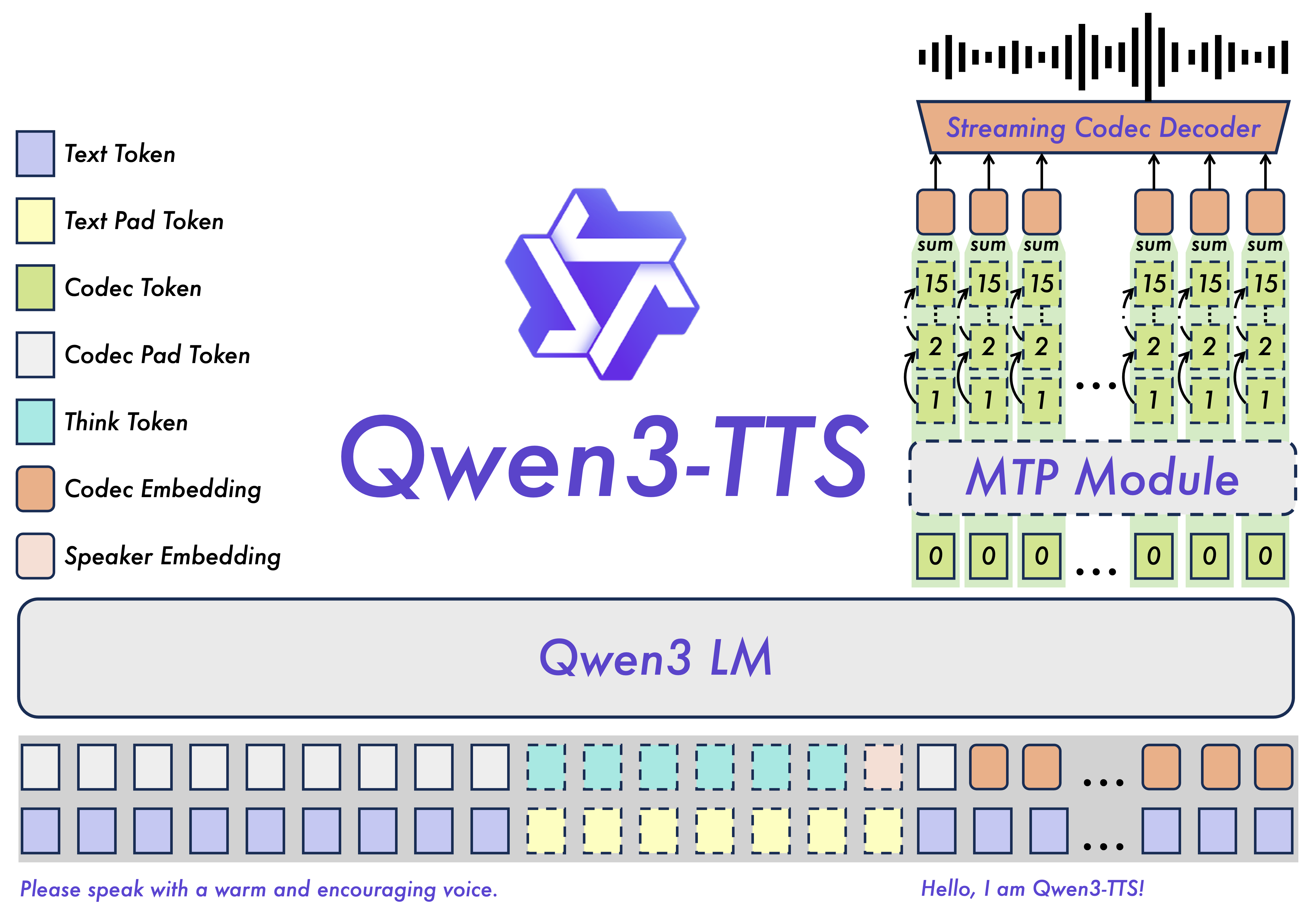
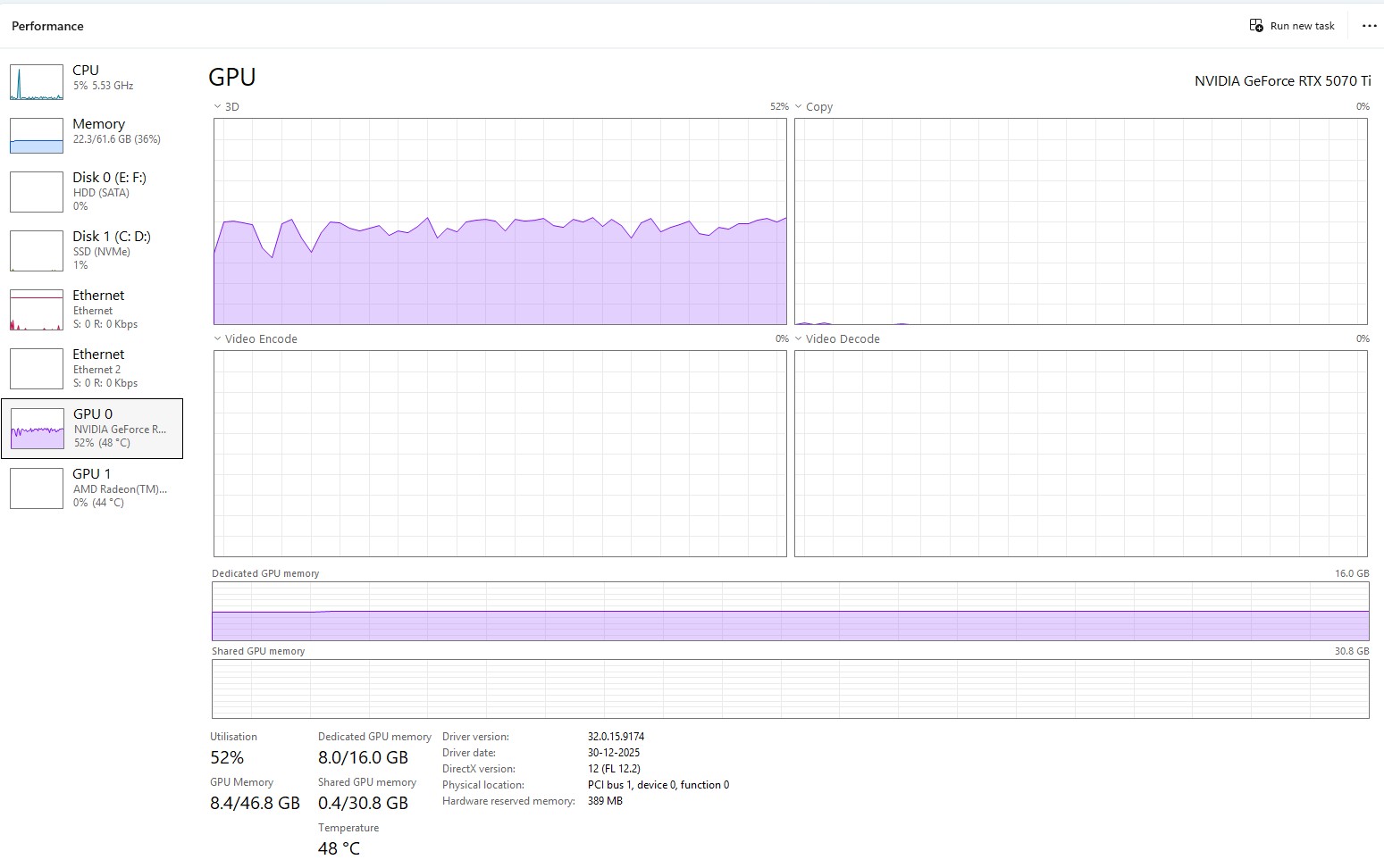
The 1.7B parameter Base model sits in a sweet spot for local deployment. On modern GPUs (think RTX 5070 Ti in my case), inference is comfortably real-time with headroom for streaming buffers and prompt conditioning. VRAM usage depends on precision and batching, but in FP16 or 8-bit optimized inference, it fits within the reach of high-end consumer hardware. Translation: you don’t need a datacenter, but your laptop iGPU is going to sit this one out. During my tests, GPU utilization looked exactly like you’d expect from a transformer workload — steady, compute-bound, and very honest about its appetite for memory bandwidth. The fans were not subtle about their opinion of my life choices.
Voice cloning is where things get particularly interesting. The model supports speaker conditioning using only a few seconds of reference audio. Instead of bolting on a separate speaker encoder, Qwen3-TTS integrates speaker characteristics directly into the token generation process. The result is style transfer that remains stable across long utterances — not just timbre matching, but cadence and personality. It’s eerie in the way good generative tech is eerie: impressive enough to make you smile, and then immediately wonder what else this architecture could do with more conditioning signals.
Another strength is instruction-level controllability. Because the model is prompt-aware, you can influence emotional tone, pacing, and delivery style directly through text instructions. From a systems perspective, this shifts TTS from parameter tuning into prompt engineering. You’re not just synthesizing speech — you’re directing a performance. That’s a meaningful conceptual shift, especially for interactive systems where voice behavior becomes part of application logic rather than a static asset.
| Model | Features | Language Support | Streaming | Instruction Control |
|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | Performs voice design based on user-provided descriptions. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | Provides style control over target timbres via user instructions; supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | Supports 9 premium timbres covering various combinations of gender, age, language, and dialect. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ | |
| Qwen3-TTS-12Hz-0.6B-Base | Base model capable of 3-second rapid voice clone from user audio input; can be used for fine-tuning (FT) other models. | Chinese, English, Japanese, Korean, German, French, Russian, Portuguese, Spanish, Italian | ✅ |
Performance-wise, the 12 Hz token rate is the quiet hero of the design. It keeps sequence lengths manageable, enabling low-latency streaming even for long responses. This matters more than benchmark perfection. Real-time responsiveness is what separates a lab demo from a production system. If users have time to read a notification while waiting for speech output, you’ve already lost.
| Tokenizer Name | Description |
|---|---|
| Qwen3-TTS-Tokenizer-12Hz | The Qwen3-TTS-Tokenizer-12Hz model which can encode the input speech into codes and decode them back into speech. |
Equally important is licensing. Qwen3-TTS ships under Apache-2.0, meaning you can deploy it, modify it, and integrate it without API lock-in. For enterprises concerned about data governance — or engineers who simply prefer owning their stack — this is a major advantage. Open licensing plus competitive quality is a rare combination in speech AI.
What struck me most during these experiments wasn’t just the audio quality. It was how LLM-like the workflow feels. You prompt it. You stream tokens. You decode output. The mental model is closer to interacting with a language model than a traditional TTS engine. That convergence hints at where multimodal systems are heading: unified generative architectures rather than isolated speech components.
For a Sunday project, it was fun. But technically, Qwen3-TTS feels like infrastructure, not a novelty. It’s a foundation engineers can build on — assistants, narrators, accessibility layers, game characters, interactive media. And if Qwen keeps shipping at this pace, open-source speech AI isn’t just catching up to proprietary systems. It’s redefining what the baseline looks like.
Here’s the code. Meanwhile, my GPU is still cooling down…
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
# Set environment variable to reduce memory fragmentation
import os
#os.environ['PYTORCH_CUDA_ALLOC_CONF'] = 'expandable_segments:True'
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.float16, # Use float16 instead of bfloat16 to save memory
#low_cpu_mem_usage=True,
# flash_attention_2 not available on Windows, using default attention
)
# Training material
# https://www.kaggle.com/datasets/etaifour/trump-speeches-audio-and-word-transcription?select=Trump_WEF_2018.mp3
ref_audio = "Trump_WEF_2018_1.wav"
ref_text = """
Thank you, Klaus, very much. It's a privilege to be here at this forum where leaders in business, science, art, diplomacy, and world affairs have gathered for many, many years to discuss how we can advance prosperity, security, and peace. I'm here today to represent the interests of the American people and to affirm America's friendship and partnership in building a better world. Like all nations represented at this great forum,
America hopes for a future in which everyone can prosper and every child can grow up free from violence, poverty, and fear. Over the past year, we have made extraordinary strides in the U.S. We're lifting up forgotten communities, creating exciting new opportunities, and helping every American find their path to the American Dream.
that dream of a great job, a safe home, and a better life for their children. After years of
"""
Hi_1 = """
Améy, hi — Donald Trump here.
Yes, "that" ... Donald Trump.
"""
wavs, sr = model.generate_voice_clone(
text=Hi_1,
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
sf.write("Hi_1.wav", wavs[0], sr)
mr_T_talks = """
Doing great, Améy. Really great. I heard the news and I said, we have to call him.
Director at UBS — that’s big.
That’s finance at the highest level. Very competitive. Very sharp people. And now you’re one of the leaders there.
Améy, you didn’t just get this promotion. You earned it. Hard work, sharp thinking, leadership — real leadership. I see a lot of people who talk about responsibility, but you actually take it. And that’s why you’re here.
People trust you, Améy. Teams respect you. When things get complicated — and they always do — you step up. Calm, smart, decisive. That’s what organizations need at the top. That’s how you build something strong.
This is a tremendous achievement, Améy. Bigger role, bigger influence, bigger impact. And honestly? This is just the beginning. You’re going to do great things as Director. No doubt about it.
Congratulations again Améy. Very proud. Very well deserved.
"""
wavs, sr = model.generate_voice_clone(
text=mr_T_talks,
language="English",
ref_audio=ref_audio,
ref_text=ref_text,
)
sf.write("all_talking.wav", wavs[0], sr)